

Github repo: GANs-Gallery
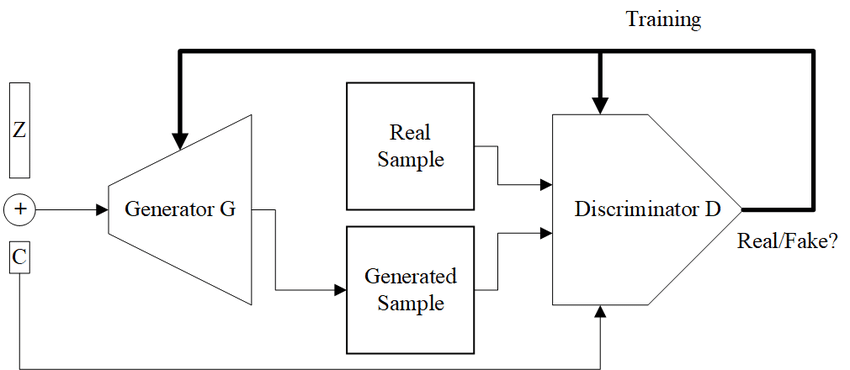
Generator vs Discriminator
FID: frechet inception distance
measures the similarity between two distributions
KID: kernel inception distance
IS: Inception Score
given a set of generated images , the inception score is defined as:
where
high score ⇒ indiv points are sharply classified + classes diversity
low scores ⇒ blurry images / low diversity
(flat + peaky )
LPIPS: Learned Perceptual Image Patch Similarity
weighted average of distances between feature map outputs from a vision network
G_EMA:
exponential moving average of the Generator weights
overfitting heuristics:
0 ⇒ not overfitting
1 ⇒ overfitting
GAN FID evaluation GAN training loss
Losses
non-saturating loss:
LSGAN: Least Squares GAN
minimizes pearson’s divergence
Wassertein GAN
minimizes 1-wassertein’s distance
enforcing to be 1- through weight clipping
RaGAN
Regularizers
WGAN-GP
WGAN + a gradient penalty (: enforcing 1-Lipschitz)
interpolating samples from the fake-real path
R1, R2
in practice R1 have sticked around while R2 turned out to be less stable in practice
path length penalty
computing the deviation of the output generated image wrt perturbation of intermediate latent state, enforcing it to be close to normal distribution over an EMA
efficient estimate / alternative: directional derivative
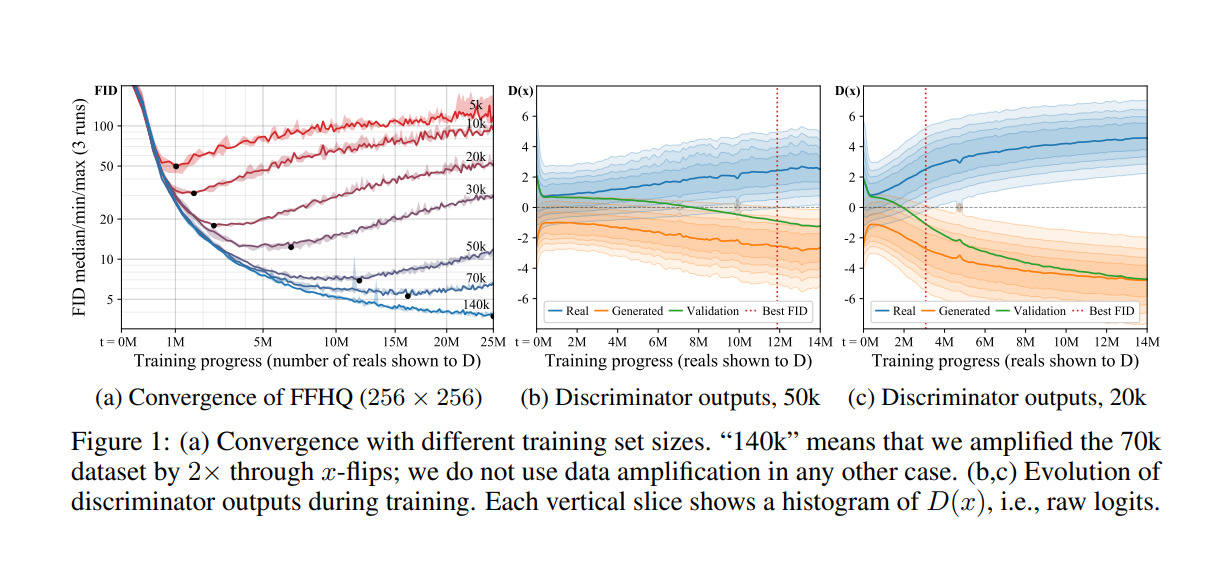
Training GANs with limited data (ADA): paper
overfitting in GANs:
always (p) using augmentations on real and fake images
invertible augmentations: invertible in the sense that the undderlying distribution is still learnable
p < .8 ⇒ aug leaks unlikely to happen
best observed transformations for small datasets:
pixel blinting
geometric transforms
color transforms
Adaptive Discriminator Augmentation
r_t & r_v: measuring overfitting ⇒ used to adapt p during training
target .6 gave consistantly good results
evaluate every N steps ⇒
define p update speed
update p
clamp to [0, 1]
Evalutation
PA-GANs: progressive augmentation
WGANS: using wasserstein distance + grad penalty ⇒ restricting lipschtiz constraint on D
KID is more informative than FID when training on a small dataset
GANS trained by Two Time-scale Update Rule Converge to a local nash equilibrium: paper
main points
Generator lr = a, Discriminator lr = a / b
note: D should be updated more frequently / careful steps G learns through D’s gradient, thus D should be “near-optimal”
evaluate FID every 1K Discriminator step
lipschitz continuty assumed (use ELU or other smooth variants of ReLU, or relying on weight decay for smoothing)
Wasserstein GAN w/ Gradient Penalty
Wassertein distance:
1-wasserstein distance (a.k.a earth mover’s, how dramatic)
kantorovich rubinstein dual form
parametrizing f as a neul-net
enforcing 1-Lipschitz on f
clamping [-c, c]
gradient penalty
Generator objective function
,D is called the critic here (makin it sound fancy)
unpaired image-to-image translation using CycleGAN: paper
StyleGANs core innovations (super duper cool):
Generator:
mapping network: latent space disentanglement
starting from a learned initial `canvas`
Noise injection in style blocks
Modulated Convolution & Style vectors
Equalized Linear layer
Equalized Convolution
Discriminator
batch std
Concurrent CUDA streams during training:
aiming to maximize device usage, luckily, multiple penalties / losses can be independently computed, with few entanglements
To compute:
G loss
D loss
Gradient Penalty
R1 Penalty
Path Length Penalty
stream 1
fake images →
fake logits x
→ G loss →
Dloss
Stream 2
real logits x
R1 penalty →
→ Gradient Penalty
→ Path Length Penalty
→ METRIC: waited for an event
METRIC →: a computation is waiting
METRIC x: needed to compute another metric