
Intro:
Realizing intelligence capable of environment interaction requires perception of the current state: environment and actor, a model of how the world responds to action and what would have happened under a different one. counterfactual reasoning is the missing piece between passively reading a scene and planning through it.
VLAs, world models and RL policies are approaches tackling the same (overall) challenge, each from a different angle. this blog focuses on world models, tho the policy and RL perspective comes up where the contrast matters. JEPA-based architectures are a recurring thread tho not the only one, the field is converging from multiple directions: representation, action grounding, latent planning and 3D structure each pulling in their own way.
Modern Origins
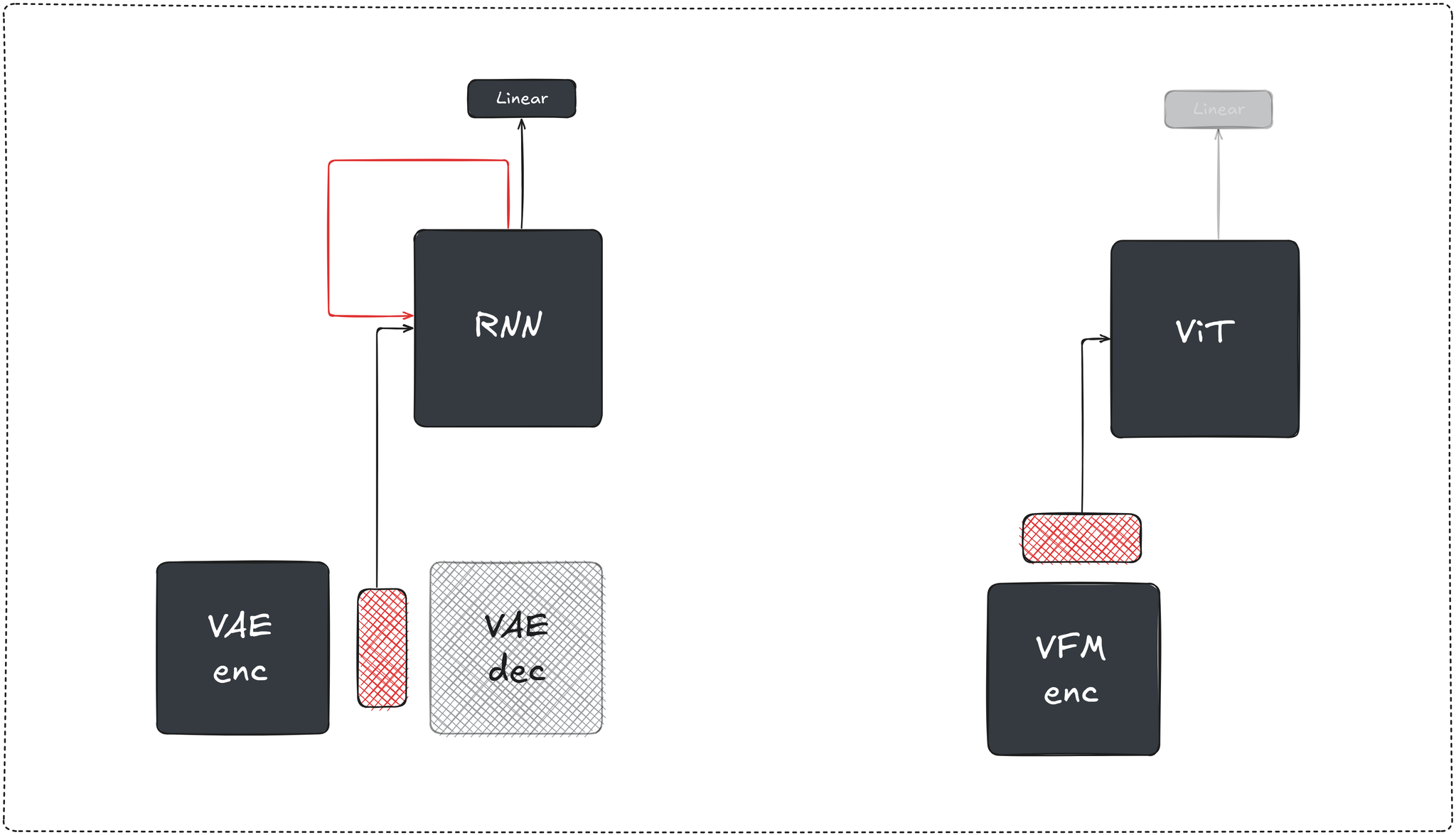
the modern definition of a world model came from a model-based RL paper titled World models (Ha & Schmidhuber), defining three components trained separately: (1) a vision encoder (VAE): compressing observations into a latent space, (2) a transition model (MDN-RNN): trained on the vision latents to predict the next latent state given the current observation’s latent representation, action and hidden state and (3) a linear layer mapping the concatenation to the actions (which were optimized using the CovarianceMatrix Adaptation Evolution Strategy (CMA-ES)).
further iterations focused on the transition model. PlaNet (Hafner et al) replaced the MDN-RNN with an RSSM, a recurrent state space model with both a deterministic stream (GRU hidden state carrying memory across timesteps) and a stochastic stream (a sampled latent capturing transition uncertainty). planning was done via CEM directly in latent space, no separate policy/action network needed.
the Dreamer family (Hafner et al) kept the RSSM but changed behaviors extraction. instead of planning at inference time, Dreamer backpropagates analytic gradients through imagined rollouts to train an actor-critic entirely inside the model's "dreams" or “imagination”, without interacting with a real environment or simulator, the policy learns purely from imagined experience.
DreamerV2 switched to discrete categorical latents and reached human-level performance on atari, DreamerV3 added a set of normalization and robustness techniques (symlog transforms, percentile return normalization, KL balancing, unimix categoricals) that collectively stabilized learning across a wide range of domains (atari, DMC, minecraft, …) with a single set of hyperparams without retuning per task hinting at the WM’s generalization potential.
one limitation of this line of work is that simple multi-step imagination rollouts accumulate model error. the learned dynamics drift off the real data distribution and long-horizon rollouts become unreliable. thus most MBRL work, including Dreamer, kept imagination horizons short.
if we were to modernize the World Models paper’s architecture today, we'd swap the VAE encoder for an SSL trained vision foundation model (e.g DINO, JEPA, …), whose representations (1) encode geometry, motion and scene structure beyond what sole reconstruction loss can enforce as demonstrated by downstream tasks performance and (2) support generative modeling directly in latent space, as shown by the RAE paper (Zheng et al), replacing the VAE encoder with a frozen pretrained vision encoder (DINO, SigLIP, …) and training a DiT on top of that space, paired with a trained decoder, enabling higher-quality generation. the MDN-RNN becomes a causal transformer operating over patch token sequences, and we’ll keep the linear controller as a placeholder for now and revisit it in later sections.
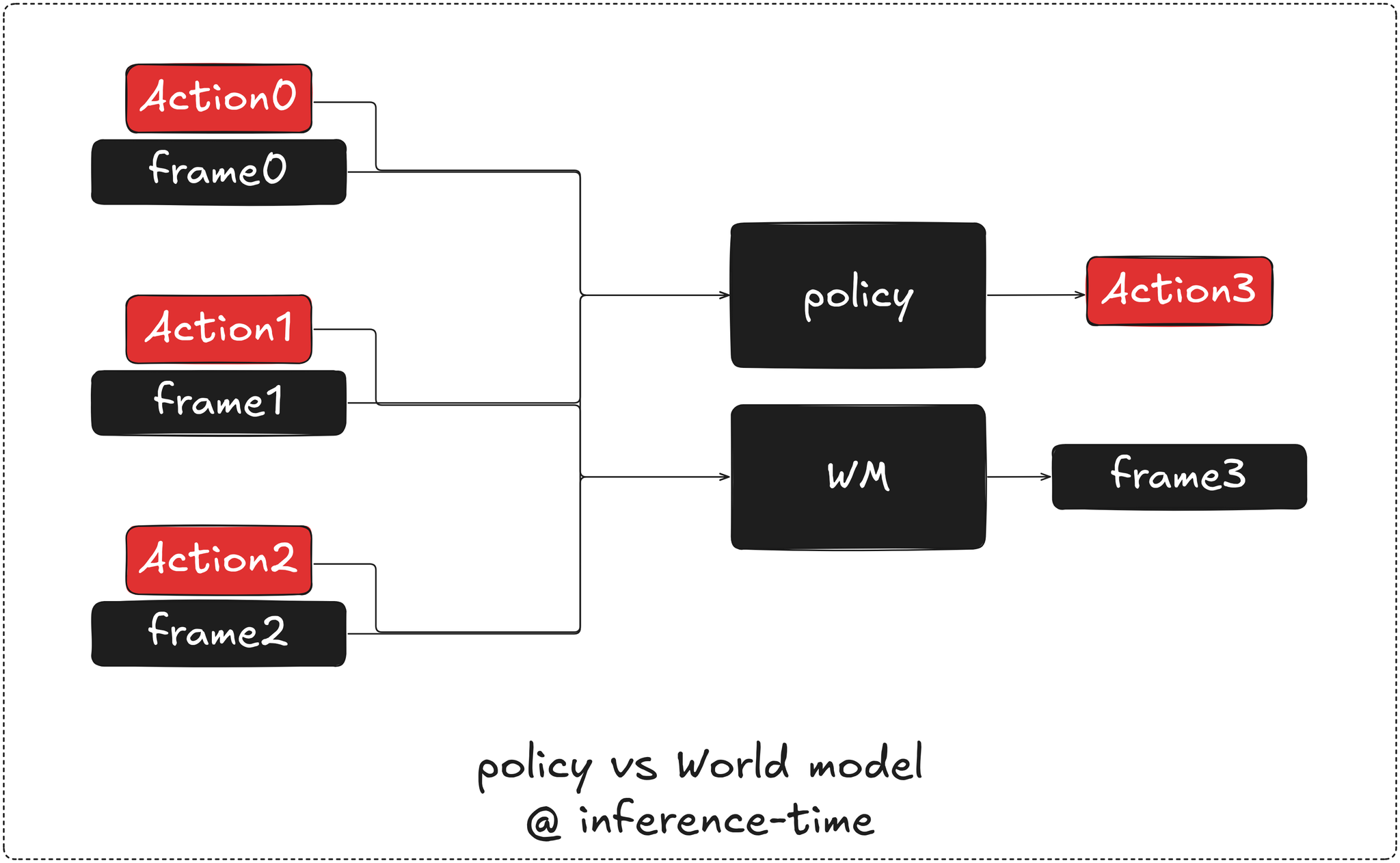
Policy vs WM
given the previous frames and actions, at inference time, a policy predicts the next action, while a world model predicts the next observation / state.
generative and predictive models, world models included, learn to produce outputs consistent with the training distribution, being best at what the data covers.
RL is fundamentally different in that angle, it optimizes a sparse, blunt and delayed reward signal over a multi-step trajectory of interactions, resulting in a costlier and looser supervision that makes training ‘notoriously’ harder while permitting exploration that can discover unanticipated trajectories, AlphaGo’s “move 37” is a known example of which.
action-conditioning is a key property that distinguishes world models from passive video prediction models, making the scarcity and cost of large-scale action-labeled data is a fundamental bottleneck for pretraining. that pushed the field toward creative approaches to ground action dynamics without requiring dense action supervision.
the JEPA line addresses that by doing most of the heavy lifting on action-free general video data, building a fundamental understanding of scenes, motion and physical interactions without touching a reward signal or actual control, followed by a relatively small amount of action-conditioned data to ground the dynamics and action consequences. the result is a passive predictive model of the world, not a policy, VJEPA 2 and VJEPA 2-AC (Assran et al) are prime examples of this pipeline, the former is the passive video model pretrained at scale, the latter extends it with action-conditioning for robotic control.
Genie (Bruce et al) approaches the unsupervised action problem from a different angle entirely, its primary goal is building interactive environments from internet video rather than grounding robot control, using a VQ-VAE encoder that infers what discrete latent action caused a frame transition. the resulting codebook entries are interpretable discrete codes, so the comparison is architectural rather than motivational, but the underlying mechanic of inferring action structure purely from observation transitions is the same pressure point.
as a result the world model is the environment surrogate offering a representation space encoding semantically relevant signal and the needed abstraction for planning. a common pattern across world models, tho not universal, is test-time action search, rolling out candidate action sequences inside the world model’s latent space, scoring them and picking the best which can be seen as the world model’s answer to RL’s trial and error, instead of wandering through a real environment driven by reward signal, we search inside the model’s latents at inference time.
the latent planning inside world models direction, is where the most interesting recent work lives.
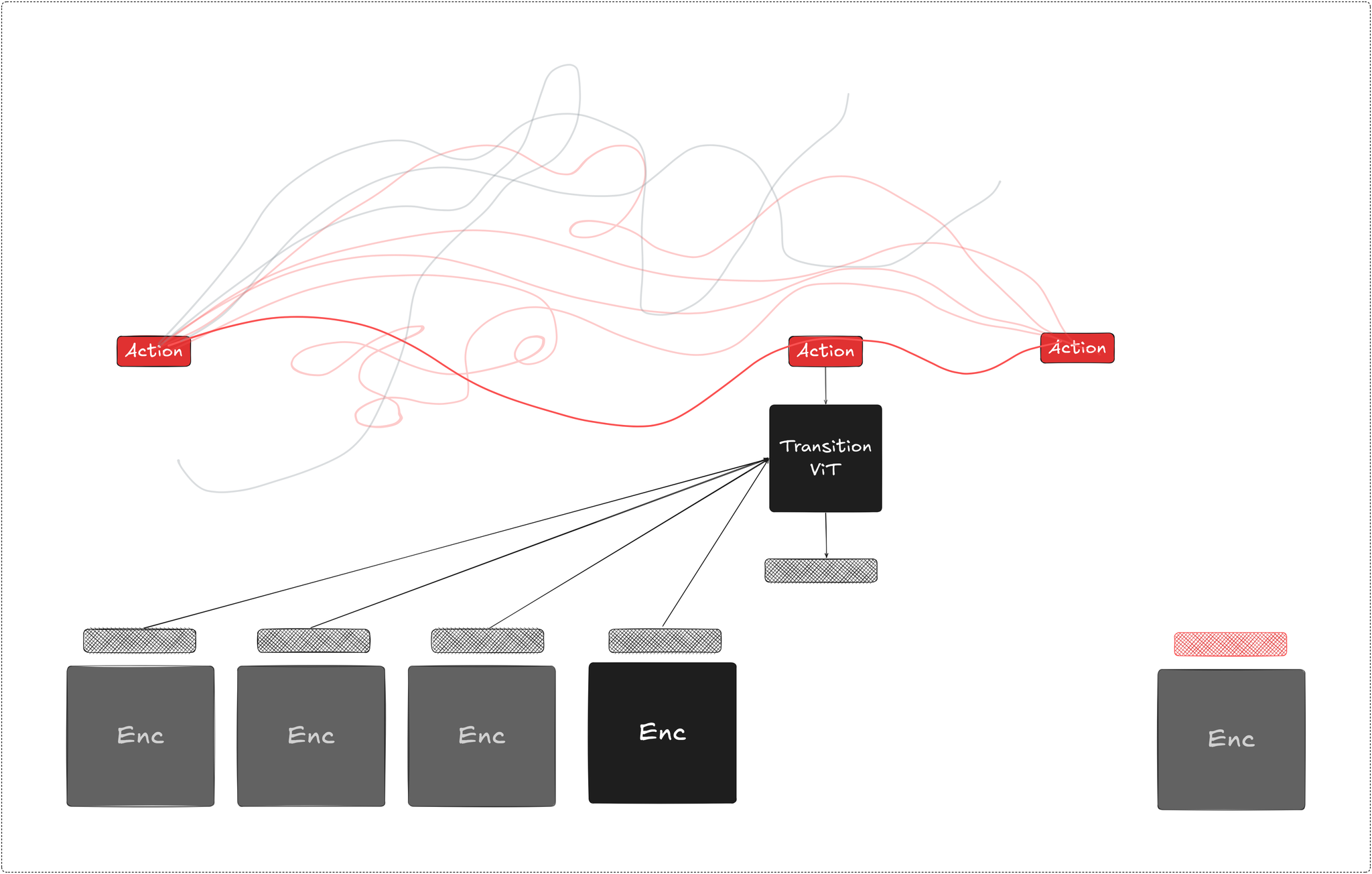
Visual Representation
the playground for the world modeling is the latent representation of observations, what signal gets encoded determines what the transition dynamics model has to work with. irrelevant details or inadvertently collapsed relevant information will feed it meaningless noise
the needed signal should intuitively include scene structure, motion, actions, objects and their interactions, while preserving identity, consistency and physics grounding as properties of the representation
SSL trained vision encoders are today’s answer to building such rich representations from large-scale data, tho recipes vary, most rely on either a contrastive or regularized objectives (SimCLR, VICReg, …), reconstruction or masked prediction objectives (MAE, iBOT, …) and combinations of both tend to win. DINOv2 (Oquab et al), for example, mixes self-distillation (DINO loss on CLS tokens), patch-level masked-prediction (iBOT) and uses the KoLeo regularizer to enforce uniform feature spreading, producing representations with strong geometric and semantic structure.
I-JEPA (Assran et al) take a slightly different approach to the “reconstruction” part. instead of predicting masked pixel patches given the visible ones, it predicts the latent representation of masked patches given latent representation of the rest. shifting prediction from pixel space to representation space is the core design choice, which allows the encoder to discard lowest-level details and shape latent geometry around semantic consistency and higher-level perception as the primary learning signal, resulting in a weaker coupling and no forced isometry back to pixel space. I-JEPA argues conceptually and LeWorldModel (Maes et al) among papers confirms empirically that adding a pixel reconstruction term to the objective doesn’t improve and slightly hurts representation quality.
beyond the encoder, JEPA training involves a predictor trained jointly end-to-end with the encoder, the module responsible for anticipating target representation from the context representations. in video settings like V-JEPA, the predictor learns to anticipate future spatiotemporal representations from current context, acting as a temporal transition function and pushing the encoder to capture what’s predictable across time.
Action Planning
given a world model that reliably predicts future latent representations, and beyond simply training a policy inside the model's imagination, the question becomes about extracting action sequences from it, which is where approaches diverge. some invert observations post-hoc via an IDM, others search inside the model at inference time via MPC, pairing planning with a learned value function to amortize search into a policy as in TD-MPC2 (Hansen et al), or composing a diffusion world model with offline RL (Deb et al) to distill trajectories into reusable behavior. others collapse the separation entirely via joint video-action modeling.
IDM: Inverse Dynamics Model
IDM is the simplest (and laziest) sidestep to action-conditioning in the forward model. instead of conditioning the predictive / transition dynamics model on previous actions, using consecutive frames / observations it deduces the transition-causing action, or formally:
the main benefit being that large-scale video pretraining is mature and available at scale, directly repurposed for the task. a separate IDM model is trainable on top using action-conditioned data much more efficiently.
UniPi (Du et al) is the clearest instance of this paradigm, it’s a text-conditioned video diffusion model used to generate future frames, with an IDM that runs over consecutive frame pairs to extract motor commands.
tho from a modeling perspective, this formulation feels intuitively off. instead of conditioning on the full trajectory of actions and resulting observations, and action grounding is delegated to a separate, single-step conditioned inversion model that has no perception to neither the full observations evolution along time, nor the action trajectory up until the current one.
structurally decoupling the observations and actions modeling by design permits the video model predict future observations that are not reachable under the IDM action space, furthermore the IDM operating at atomic actions fails to account for the trajectory of past actions.
MPC: Model Predictive Control
rather than inverting observations post-hoc, a more direct approach is treating the world model as an environment surrogate and search inside it at inference time. given a goal latent and a current state , we roll out candidate action sequences through the predictor, score each trajectory against the goal, and execute the best one. replanning at every step as a new observation arrives.
open-loop planning:
closed-loop MPC plans over a horizon , commits to the first action, observe the outcome and repeat, substituting real environment interaction with offline rollout search.
the simpler open-loop variant optimizes the full sequence once and executes it without replanning, which is cheaper but accumulates model error uncorrected over the horizon.
one of the most commonly used optimizers for this in latent space is the Cross-Entropy Method (CEM). it maintains a distribution over action sequences and iteratively refines it by sampling a population of candidates, scoring them and keeping the top- elites to refit the distribution.
DINO-WM (Zhou et al), VJEPA 2-AC, LeWorldModel, and others follow this loop, each pairing a frozen or jointly trained encoder with an action-conditioned predictor and CEM at test-time toward a goal latent.
the shared assumption is that the latent space is compact and smooth enough that CEM converges in a handful of iterations making inference-time search tractable without per-task planning networks.
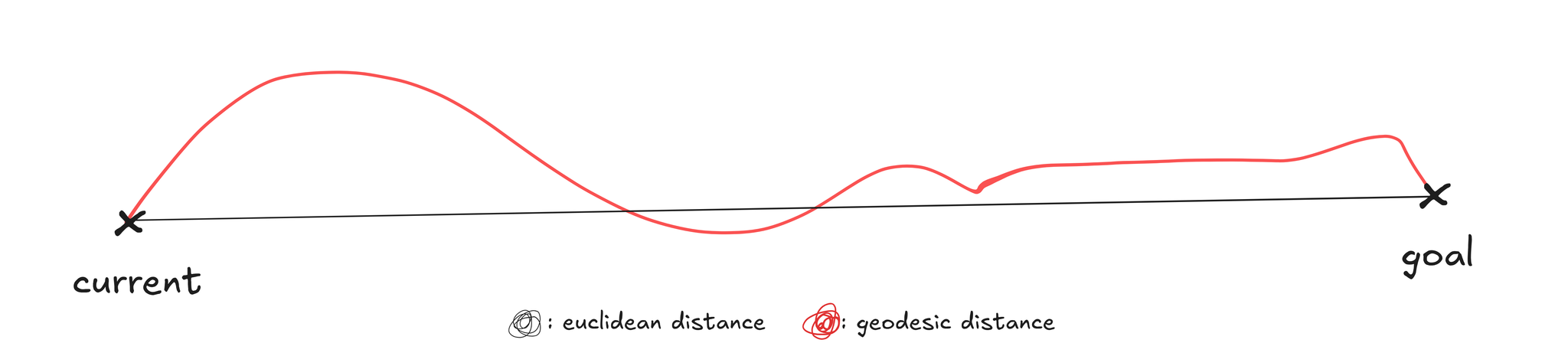
since the predictor is differentiable, gradient descent directly through the unrolled rollout is a natural alternative, backpropagating the goal cost through and updating directly, without sampling. in practice it underperforms CEM since frozen SSL features like DINOv2 produce highly curved latent trajectories, making the planning objective highly non-convex, where euclidean distance a poor proxy for geodesic progress and gradient steps point in misleading directions.
CEM's population-based search is more robust to that geometry, at the cost of higher compute. fixing this requires shaping the encoder geometry itself during training, which we'll get to in the next section.
World Action Models
an adjacent paradigm collapses the separation between world modeling and action extraction entirely, jointly predicting future frames and the actions that caused them in a single model:
DreamZero (Ye et al) is a recent instance of this, a 14B model, built on the Wan2.1 autoregressive video diffusion backbone, that jointly generates future frames and continuous actions end-to-end.
structurally it decomposes as video prediction followed by an implicit IDM, but unified under a single training objective where video and action latents are jointly denoised in the same forward pass, forcing mutual consistency between predicted futures and predicted actions at every noise level rather than delegating inversion to a separate module with no shared gradient. the result is over 2x task progress in generalization over SOTA VLAs on robot experiments, cross-embodiment transfer from 10-20 minutes of video-only demonstration and full embodiment adaptation to new robots
the core argument is that jointly modeling actions and observations forces the model to predict action-consistent futures, directly addressing the structural failure of the decoupled IDM noted earlier, where the video model has no obligation to stay within the reachable action space.
Variants and Interesting Directions
Latent Geometry: Temporal Straightening
frozen SSL encoders like DINOv2 produce highly curved latent trajectories, where consecutive velocity vectors point in inconsistent directions. the planning objective is highly non-convex and as a result and gradient descent through the rollout consistently underperforms CEM, population-based search navigates the geomtry better at the cost of compute.
Temporal straightening for latent planning (Wang et al) studies and addresses this at training. motivated by the perceptual straightening hypothesis in human vision and similar AI-generated video detection application (ReStraV), the paper trains the encoder and predictor jointly with a curvature regularizer that maximizes cosine similarity between consecutive velocity vectors:
shaping the encoder geometry at training time rather than projecting post-hoc into a nicer space. straighter trajectories make euclidean distance a better proxy for geodesic progress. improving the planning hessian’s conditioning and letting gradient-based planning recover; open-loop planning success improves by 20-60% and MPC by 20-30% over frozen DINOv2 baselines.
interestingly, LeWorldModel (a 15M params model) reports temporal straightness as a purely emergent property. its objective is and , a per-timestep isotopic gaussian regularizer introduced in LeJEPA (Balestriero et al), with no cross-temporal coupling terms, yet the encoder’s latent geometry converges toward low-curvature trajectories as an implicit bias of optimization.
Hierarchical Planning
LeCun’s 2022 position paper laid out hierarchical planning as a core requirement for autonomous intelligence, envisioning high-level goals decomposition into subgoal sequences with the world model predicting at multiple levels of abstraction.
flat MPC runs into two compounding issues at long horizons; model prediction error accumulates over the open-loop rollout used during optimization and the effective search space for methods like CEM grows rapidly with horizon length. longer horizons make the cost landscape both higher-dimensional and noisier, which degrades optimization quality and ultimately hurts closed-loop performance despite replanning. non-greedy tasks where short-horizon objectives such as Franka pick-and-place exposes that failure sharply.
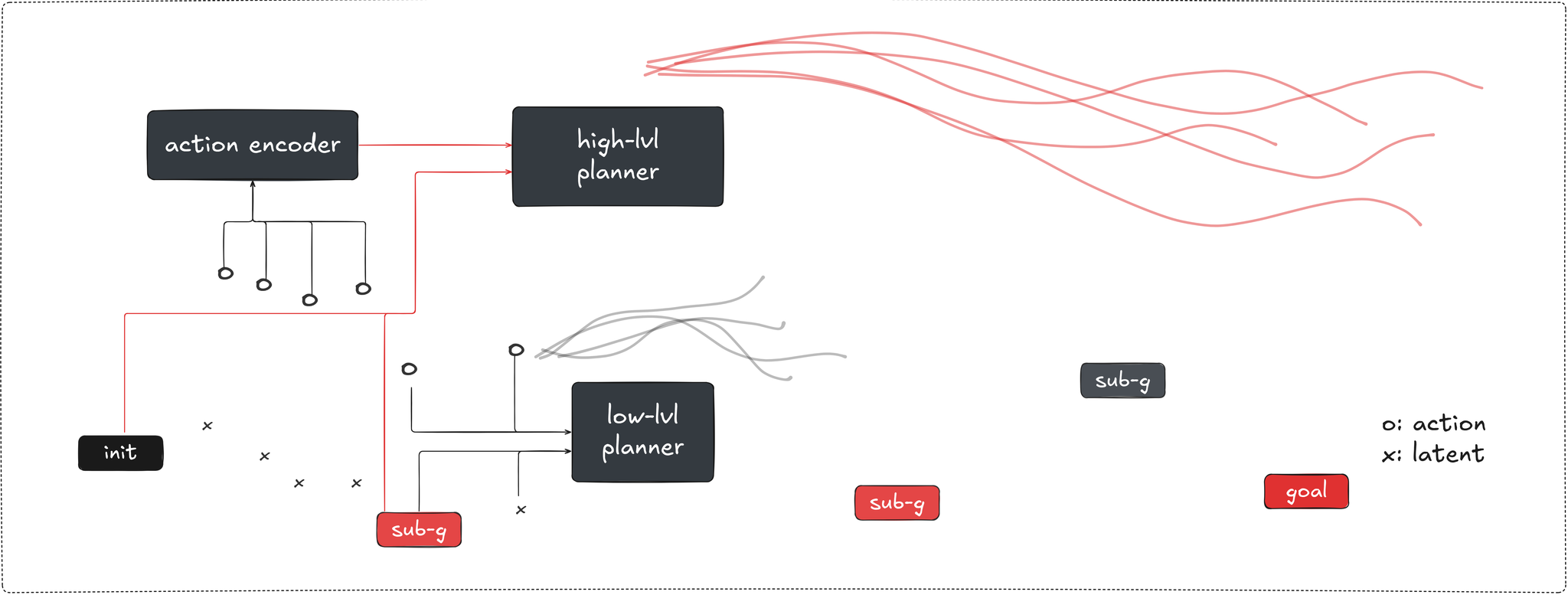
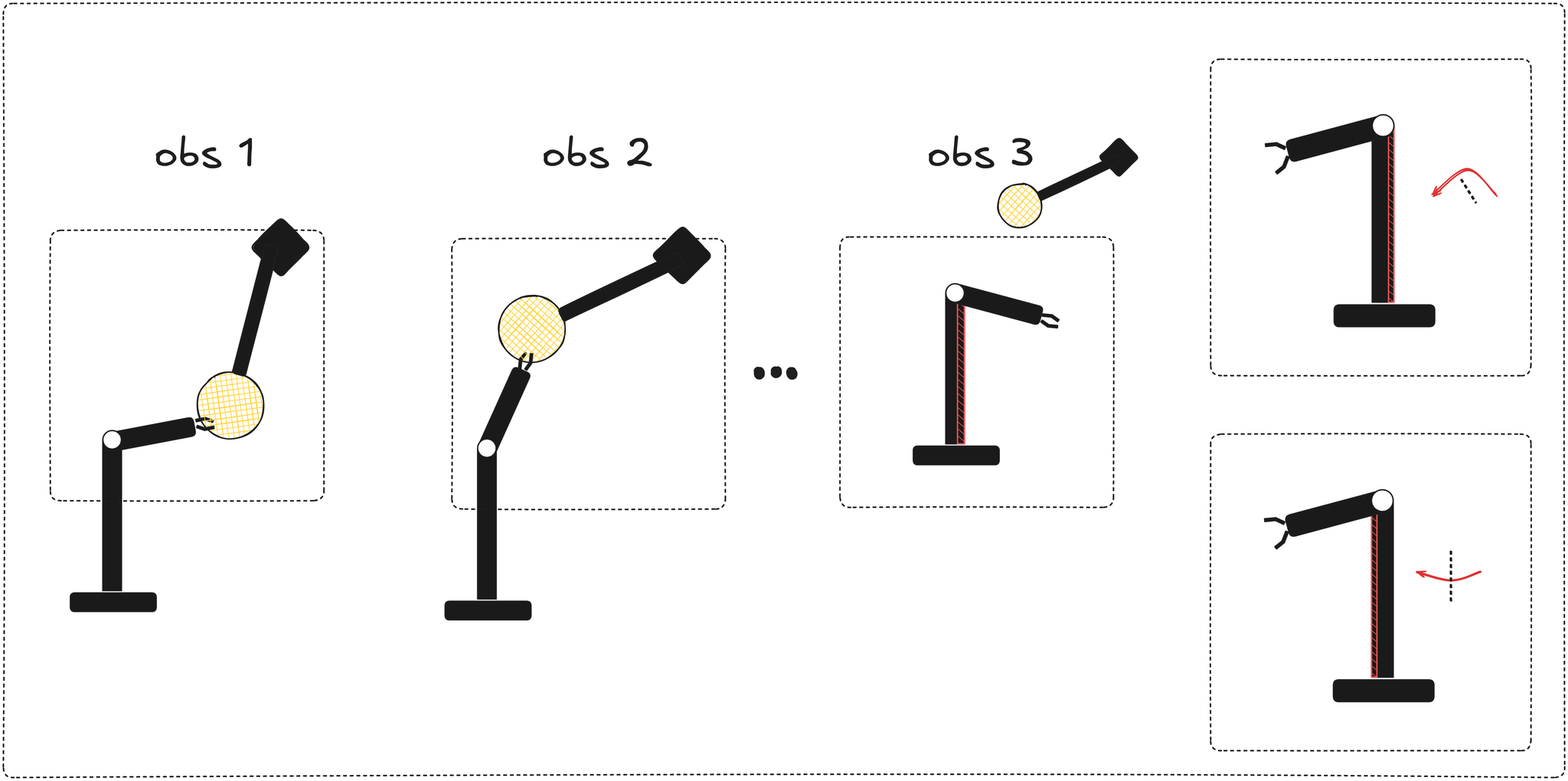
Hierarchical Planning with latent WMs (Zhang et al) trains two predictors on top of the frozen pretrained encoder. the low-level predictor handles step-by-step primitive transitions in closed-loop receding-horizon MPC. the high-level predictor operates over latent macro-actions produced by a learned action encoder that compresses variable-length sequences of primitive actions without assuming a fixed temporal stride. at inference the high-level planner runs CEM toward producing intermediate latent subgoals, the low-level planner executes toward the first one in closed-loop MPC.
3D World Models
the approaches discussed so far predict in 2D patch feature spaces representing observations and not states. tho DINO features correlate with 3D structure but predicting in 2D feature space isn’t the same as modleing 3D physical displacement direcly. World Labs is the highest profile bet on that distriction, building toward what Fei-Fei Li frames as spatial intelligence arguing that 3D as the right representational substrate for world modeling with geometric structure as a first-class output rather than an emergent byproduct of 2D generation.
on the research side, PointWorld (Huang et al) implement that for robotic manipulation. states and actions are both expressed as 3D point flows in a shared space, the scene state is a full point cloud backprojected from RGB-D images. robot actions are converted to dense 3D point flows over the robot’s geometry via forward kinematics from the URDF analytically. the model then predict per-point 3D displacement over the full scene jointly, robot and env together.
predicting in 3D unlocks supervision over occluded contact regions where the gripper is hidden behind objects, forward kinematics still produces a complete dense signal over the interaction region from joint configuration and the model is trained without supervising occluded scene points yet generalizes better than its noisy ground-truth annotations in those regions after training.
since robot and scene share the same geometric space the formulation is embodiment-agnostic, using the URDF to define and project action space. PointWorld, trained on ~2M trajectories across a Franka and a bimanual humanoid, runs at s latency and demonstrates zero-shot manipulation from single RGB-D capture across rigid, deformable, articulated and tool-use tasks without demonstrations or post-training.
Conclusion
no single approach has a clean monopoly on the problem. approaches vary from training policies inside model imaginations, using world models as inference-time planning substrates, collapsing the separation into joint world-action modeling, to arguing the state space should be 3D to begin with.
the solution that eventually sticks will probably look like none of these cleanly, most likely a hybrid borrowing the representation philosophy from one direction, the planning machinery from another, action extraction from a third, and likely pulling from adjacent ML subfields in ways that aren't obvious yet. the point right now is charting the design space well enough that the convergence, when it happens, is principled.
References
the following papers constitute the main references for the ideas discussed in this article
Ha & Schmidhuber: World Models
Hafner et al: Dreamer
Bruce et al: Genie
Oquab et al: DINOv2
Assran et al: I-JEPA
Assran et al: V-JEPA 2
Balestriero et al: LeJEPA
Maes et al: LeWorldModel
Zhou et al: DINO-WM
Du et al: UniPi
Ye et al: DreamZero
Huang et al: PointWorld
Wang et al: Temporal straightening for latent planning
Zhang et al: Hierarchical Planning with Latent World Models