
UC Berkely’s CS285, ETH zurich’s Robot learning course and beyond
Imitation Learning / behavioral cloning
the supervised outlier in RL
: action
: state
: observation
the state is complete physical observation of the world
an observation is a snapshot / image of the state
transitioning from a state to another inherits the markov property
perfect training data distribution maybe harmful for imitation learning in a sense that the policy can easily go off-track on very narrow and deterministic paths can be easily in contrast of diluted training data distribution with mistakes and corrections by the expert in many diverse states, providing corrections of mistakes independently of the state will result to mistakes uncorrelated to the state while preserving the optimal action correlated to the state
continuous action distribution policy
mixture of gaussians
latent variable models
using conditional variational autoencoders
diffusion models
diffusing on the latent action representation dimension and not the temporal observation dimension
discretization with high dimensional action spaces
autoregressive descretization
generating action vector elements as a sequence
limitations & bottelnecks
non-markovian behaviour
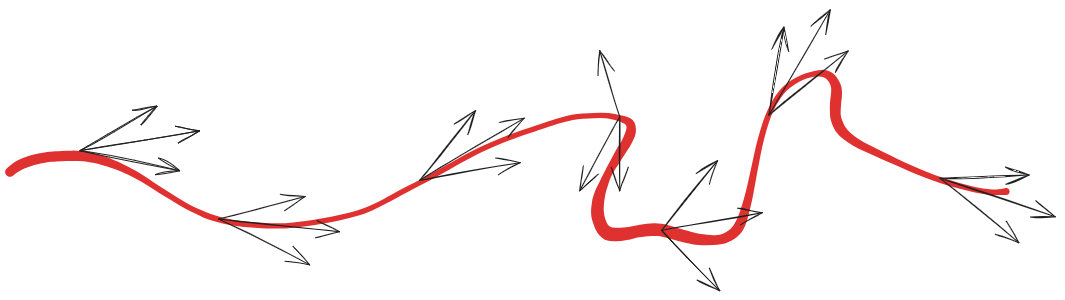
multimodal behaviour: observing different actions based on the same observation
→ more expressive continuous distributions
vs
→ discretization with high dimensional action spacesa
Actor Critic
value function estimator: train on
reward bootstrap estimator:
actor critic algorithm:
sample using
fit to sampled reward / bootstrap
evaluate
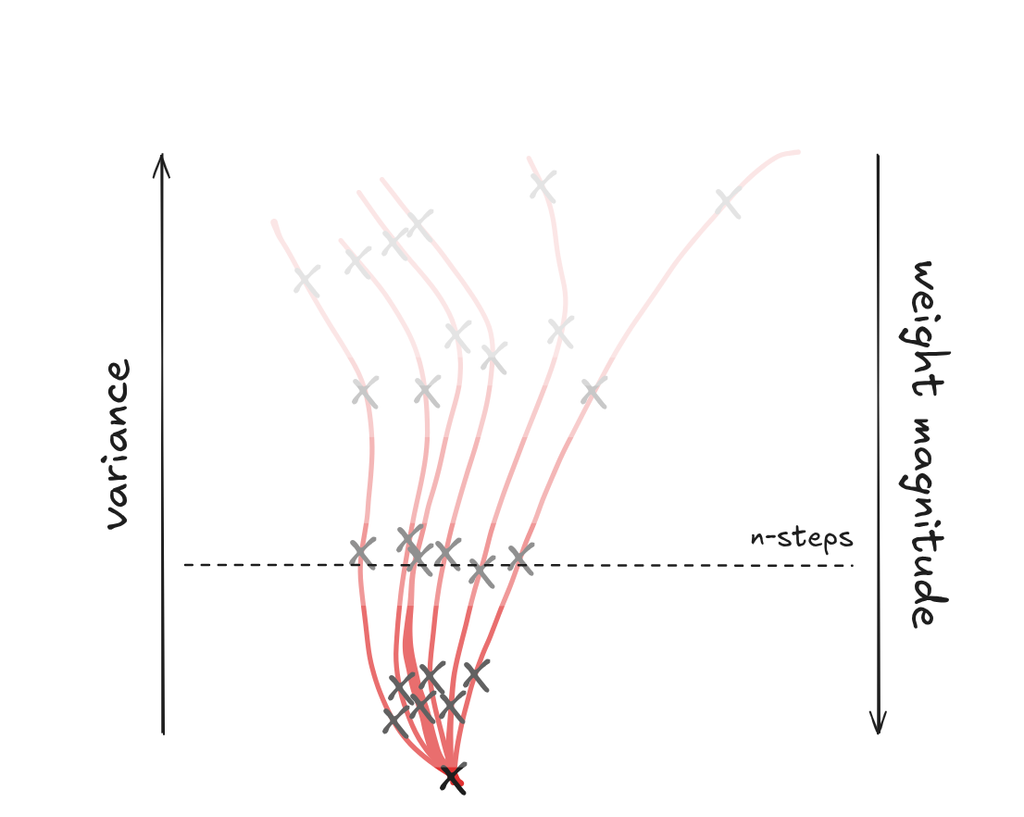
Discount factor
applying an exponential decay over time to rewards
equation (1) (which matches the critic) applies the discount factor starting from the current action step
equation (2) applies the discount factor starting from the initial step
equation (3) is same as equation (2) and additionally discounts the gradient (decaying the importance of future actions / steps)
bias-variance: grad weighting
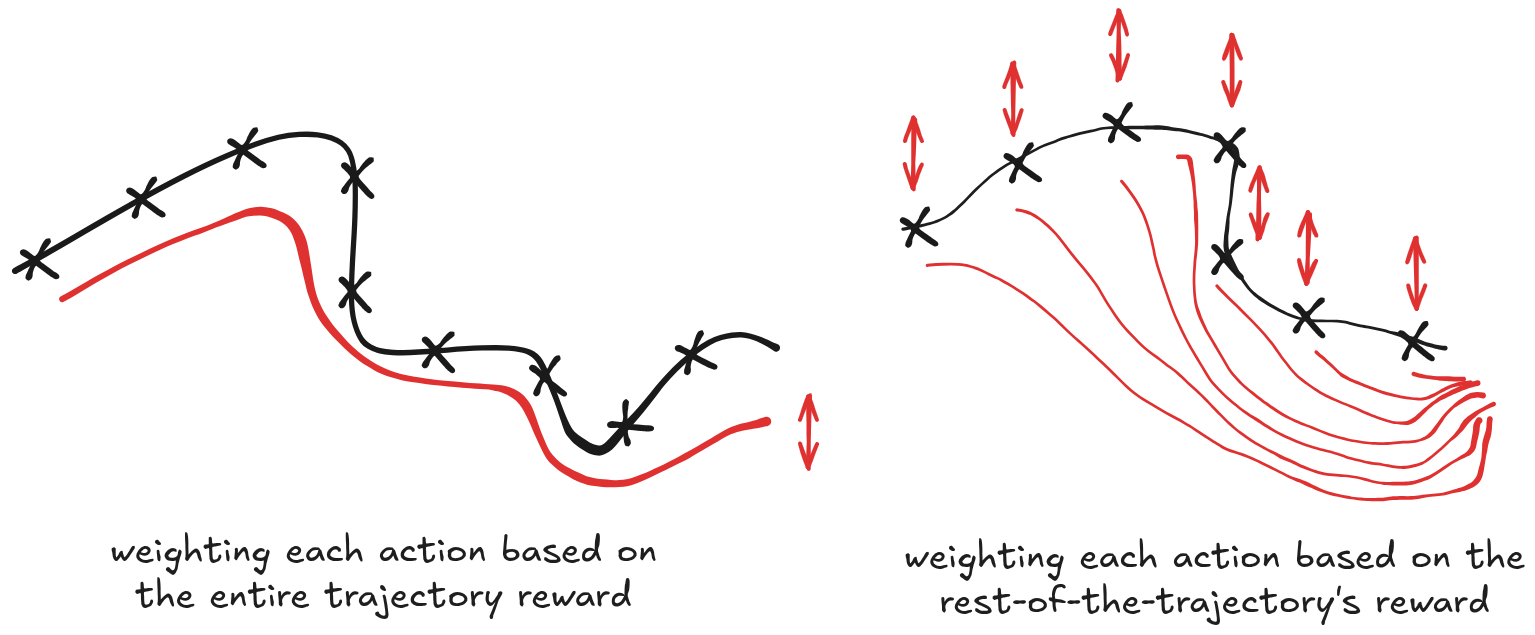
in gradient based algorithms the gradient is set of state-conditioned actions taken on following a batch of sampled trajectories using the policy, each action log prob weighted by some value (could be reward-to-go, estimated value function, advantage, discounted advantage, …)
the weight factor is what determin how more/less likely that state-conditioned action to be taken
baseline: using rewards as the weight using a monte-carlo estimator is compute expensive (requires interacting with the environment) which is usually overcome by using less samples (commonly a single one)
⇒ leading to a variance problem (too few samples)
critic: using a learned / estimated weight (fitted function, actor critiic, …) makes reducing variance easier (sampling from a learned function is much cheaper)
⇒ introduces bias (estimator error) to the equation
best-of-both-worlds solutions
critic as a baseline:
n-step returns:

RL algorithms typography
policy-gradient methods: gradient-based optimization of the expectation of reward over policy-sampled trajectory
value-based methods: estimate / learn V- or Q- function
actor critic: learn V- or Q- function and use it to optimize the policy (e.g better )
model-based methods: learn transition model + improve the policy
Policy Gradient
sequence modeling, !! optimizing the expected reward !!
Q-function, value-function and advantage
policy-gradient gradient derivation
effectively:
sample trajectories following the current policy
up-/down- weight the log-prob of the trajectory using it’s expected reward
Off-Policy Policy Gradient
updating the current policy using previous policy actions / transactions suing importance sampling