

Neural networks, at their core, are space-to-space transformations, each layer warps and bends a high-dimensional manifold, carrying points (data points) from one representation to another (discussed in details in an old blog). But there's a critical flaw when naively applied to sequences: we treat each token as if it lives in isolation
The isolation problem in sequential data
many ML tasks involve sequential modaly including language, video, audio, …
a naive adaption of neural networks for such tasks would be computing the output prediction / latent representation of each chunk / token seperately and somehow aggregate’em to get a representation of the entire sequence
but these aren't bags of disjointed pieces, but rather, each holding an infinitessimal part of the sequence semantics, emerging from tokens relationships.
Consider the word "bank" In "I sat by the river bank" it's a geographical feature where it’s usually used as in the financial institution, the word “nail” could be a finger nail or a tool at a carpenter or a blacksmith workstation. The token itself is identical; its context is what “shifted” it’s meaning.
Similarly, a high-pitched audio frame is mundane in opera but jarring in death metal. A bright flash in a video might signal a scene transition in a mostly dimmed scene or just another normal frame in a colorful cartoon
thus processing each token seprately won’t cut it, what’s missing here is some sort of a communication scheme, a mechanism to share context across all tokens
The RNN Era: a single messenger
Early solutions involved Recurrent Neural Networks. The idea was elegant: maintain a single state vector, a messenger, that runs through the sequence, getting updated by each token. The messenger starts blank, absorbs token 1, transforms, absorbs token 2, transforms again, and so on.
But there's a fundamental bottleneck: everything must pass through one bottlenecked state (the messenger). Later tokens can override earlier messages. tokens at the end of a long sentence might erase the context that the word "stool" established at the start that would help mitigate the "nail" semantic confusion. Information is squeezed and shared through a single state, not shared
LSTMs and xLSTMs improved this by creating separate memory lanes: short-term, long-term, even exponentially-long-term, but the core problem partially remained since inter-token communication was still mediated by a single vector. Tokens couldn't have direct information exchange. They could only “leave notes” for the messenger, hoping they'd survive the journey
Transformers: Token-Level Communication
the core shift was introducing simultanous and direct token-to-token communication and giving up on the sequential processing nature of RNNs
The high level idea is: instead of a single mediator / messenger, we create a fully connected communication graph where each token can broadcast its message to all others and each can decide whom to listen to
The Flock of tokens: How attention creates collective context awareness
Each token in the sequence is represented by a vector / point in a high-dimenson space thus each sequence is a “flock” of points in that space and our goal is to have a good representation of the entire sequence by their position in that space
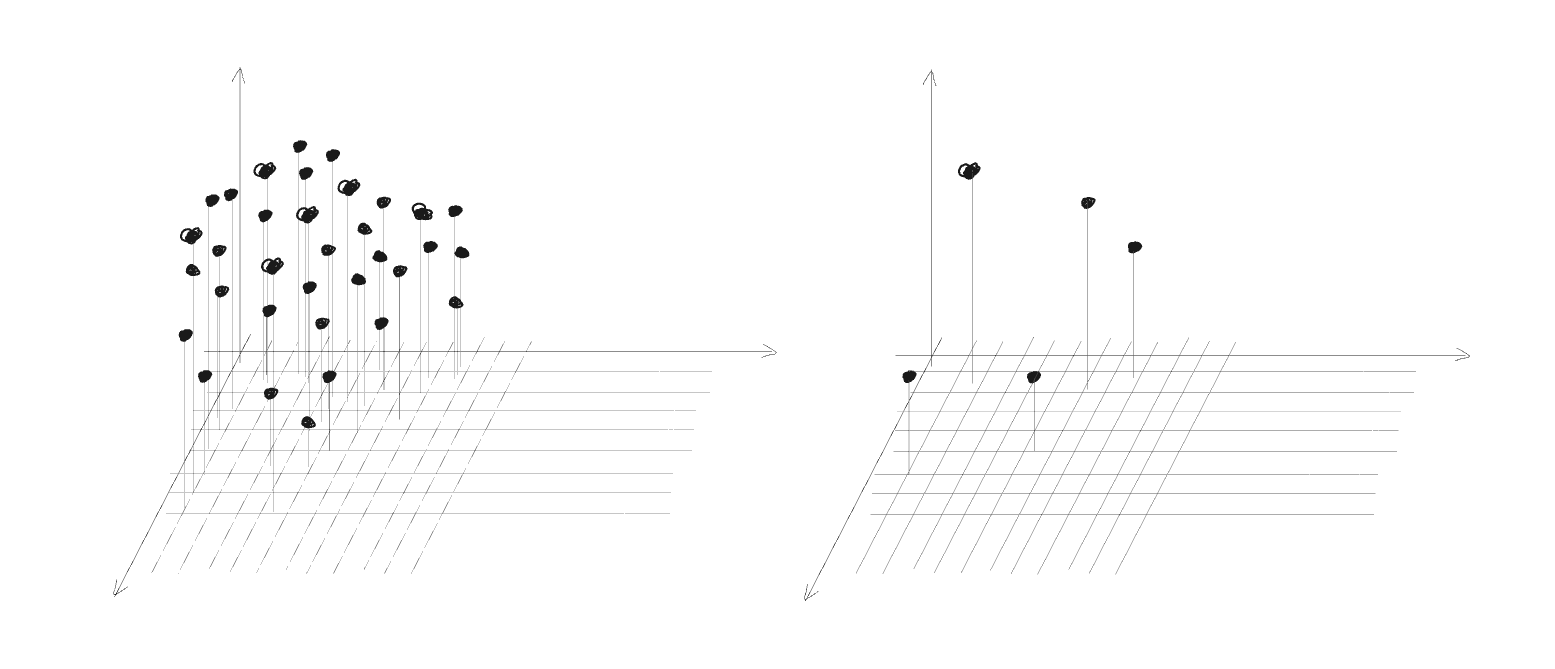
The most basic communication mechanism would involve each token attrackting all other tokens in that space (which’s equivalent to having some sort of an aggregation in that space)
but if we give it a second thought that doesn’t illustrate our goal in these modalities sometimes we’d rather some tokens would repell other tokens from them, or even push them toward different regions in the tokens space e.g the words “ocean”, “leaks” and “emergency” would ideally push the word “nail” to a region of that space conveying that meaning (a nail in a ship’s repair toolkit) which not necessarily close to these words in that space
thus each token would have its direction to push other tokens to, as in “broadcasting a message” / recommending a direction
we’ll refer to that direction as the Value vector
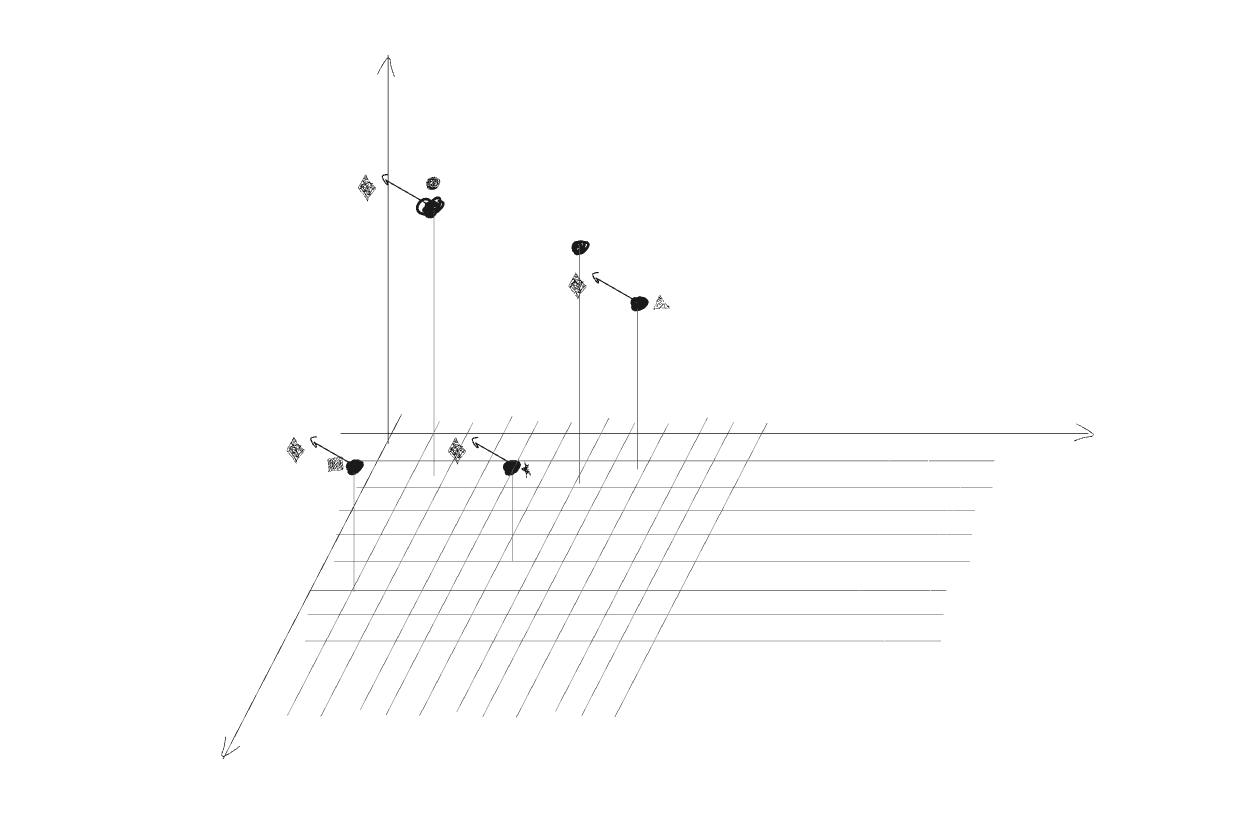
the second part of the communication mechanism is the receiver’s part which would monitor which direction (:message) will each token follow, if each token followed all shared vectors, all tokens would move relatively the same in the space, as a result, a selection and weighting mechanism is therefore required to control the magnitude of each token’s movement along these suggested directions , e.g the word “nail” would care most about “ocean”, “leaks”, and “emergency” and not so much about “breakfast”, “music”, “storm” (with different degrees)
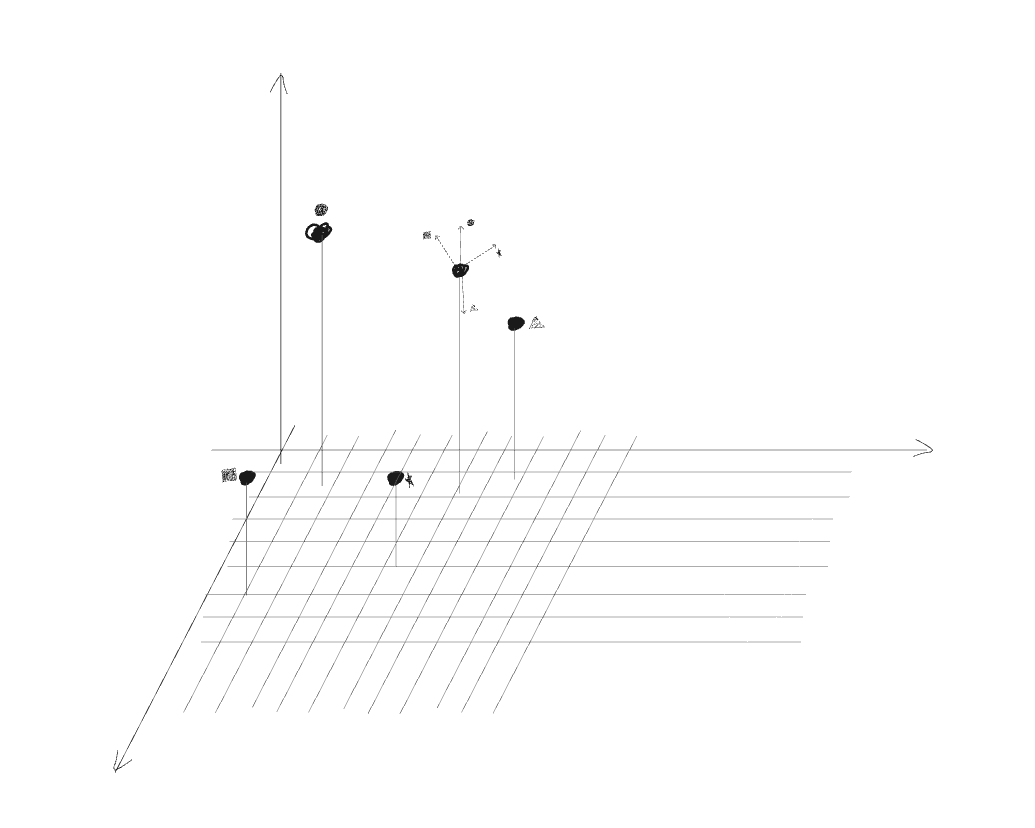
a simple solution would be creating some sort of a vector representation of each token and use these to determin similarity / relevance or “attention” for each token pair. We’ll compute a similarity score of both the “emitter” token and the “receiver” token in a dedicated space for each pair of tokens.
A better solution actually would differentiate the “emitter” and “reciever” in the similarity computation, intuitively some tokens may benefit from conveying certain semantics when “convincing” other tokens to follow it’s direction, and would look for different semantics when deciding to follow or not other tokens e.g the token “cat” might look for color, shape and size cues to better determin personality treats, habbits and capabilities of that cat (an adult serval cat is quite different from a brown scottish fold kitty) while conveying playfullness, cuteness and domestic setting would be quite the same across all cat species and sizes.
to solve that we’ll use different transformations to go to the “similarity” space based on the token being the “emtter” or the “receiver” and those will be called the (query) and (key) vectors respecively.
the similarity score between the token-to-move’s vector and each other token’s vector we’ll be refered to as the , and used to weight the other token’s vector, in other word the distance to move in the suggested direction
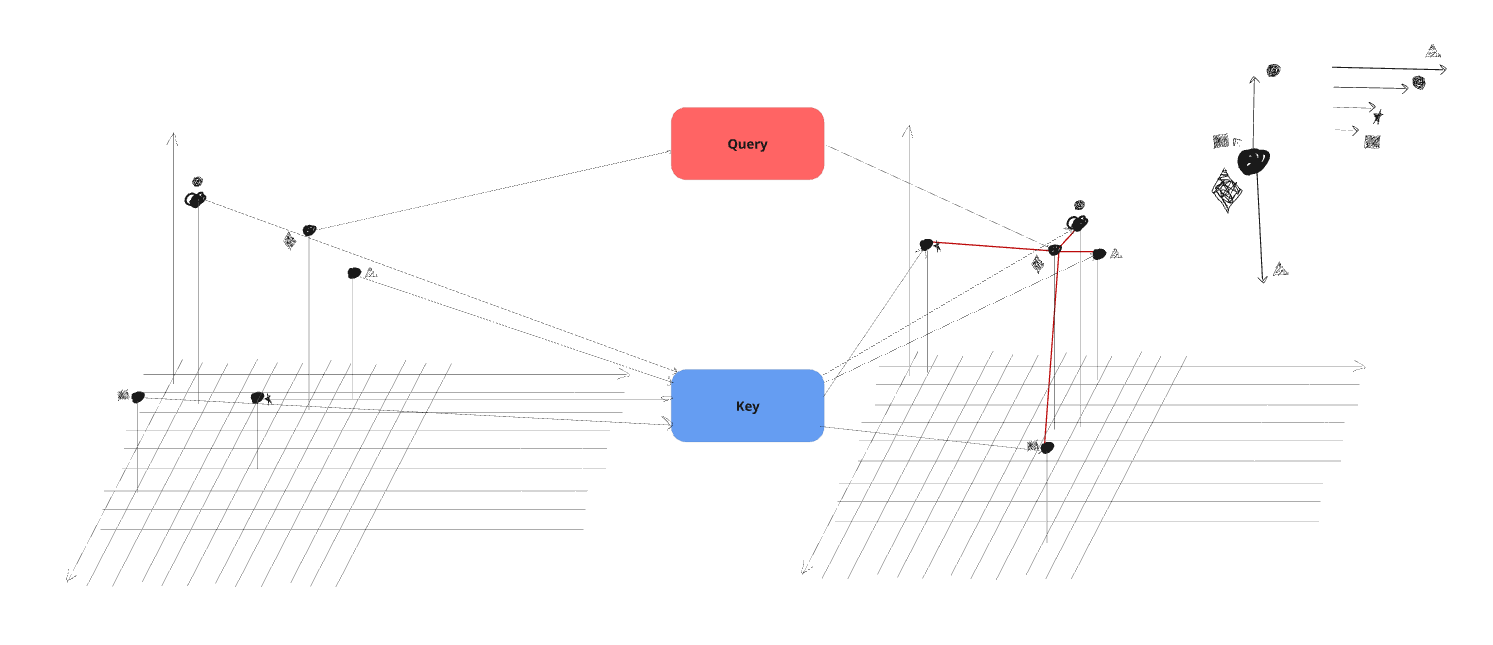
the high level image is: we let each token push all other tokens to some region in the space, the magnitude / force of that push is determined by how meaningful should the influence of that token on each other token be, the result is a communication mechanism letting tokens exchange and collectively emerging context awareness
Communicate, across multiple semantic levels
following each round of communication in token space, we’ll transform each token seperately to the next, higher level (features wise) space using the same neural network / MLP, a transformer block represent the communication phase + transformation phase.
A transformer model is doing multiple rounds of alternating communication and individual transformation i.e have multiple blocks, so that at each level we have tokens communication in the current space + transformation to the next space and we do that over and over again, at the end we can simply aggregage results (most commonly by averaging all token representations) to get a representation of the entire sequence
one last problem to discuss, occurs with the aggregation is that high variance may hurt the final result, if at the end of the last transformer block tokens are relatively spread across the space, a mean aggregation will be sensitive to variance, intuitively: introducing a single new token at that last space may result in a relatively large shift, in other words we’re implicitly encouraging moving all points to the same region and discouraging holding onto different semantic expression
the used solution is actually not aggregating token representations at all, but rather at the beginnening introducing a special token mostly refered to as
cls_token
that contain empty / non biased representation to any seen token during training, and we would run the transformer as exactly discussed earlier and at the end we’ll use that special token which will represent the entire sequence, in a sense that’s similar to the RNN state vector (a single vector representing the entire sequence) the difference is that we didn’t limit communication through that token but rather had all tokens (including the cls_token
) communicate pair-wise in multiple rounds, using that relief the last tokens representation spread constraint and each token will have sementically expressive representaiton at the endNotes & Abstractions
to keep the blog mostly intuition based and primarily describe the “flock of tokens” perspective few details where waved / not properly mention, the main ones being: position encoding moving from RNNs to the Transformers architecture by default we lost the tokens position / order in the sequence which is explicitly encoded in transformers unlike RNNs
Conclusion
Since its introduction the transformers architecture reshaped how we dealed with most sequences and even reframed some modalities into sequences just to gain their benefits (e.g Vision Transformers chunk images into patches, 3D data, …), I believe having this intuitive point of view on the mechanism breaks it down nicely and accessibly to new comers and may offer a great mental models to others